Enterprise AI Agent Architecture: A Practical Blueprint
A practical architecture blueprint for enterprise AI agents in 2026, covering orchestration, governance, RAG, observability, and rollout strategy.

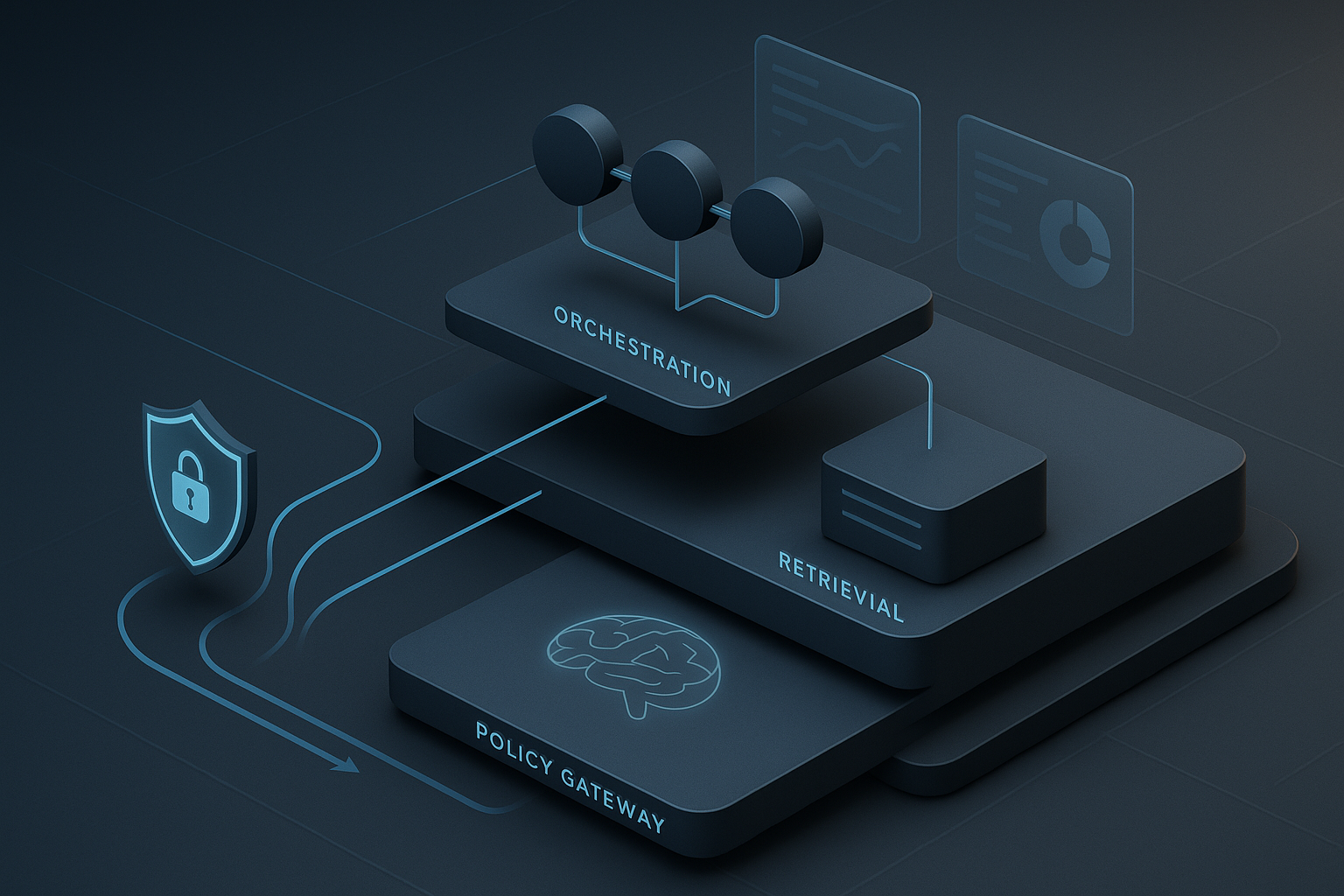
Let’s be honest: most “agentic AI” demos look impressive right up until they touch real enterprise systems.
What this covers: a practical enterprise AI agent architecture you can implement with Azure, OpenAI, Python, and .NET—focused on governance, reliability, and scale.
The moment you move beyond a sandbox, the hard questions appear fast: who approved this action, where did this answer come from, why did latency spike, and how do we stop a bad tool call before it creates cleanup work for three teams?
That’s why, in 2026, shipping enterprise agents is mostly an architecture problem—not a prompt-writing contest.
This is a practical blueprint for teams building with Azure, OpenAI, Python, and .NET, and trying to get from pilot excitement to production confidence.
The failure mode almost everyone underestimates
Most teams don’t fail because the model is “not smart enough.” They fail because the system around the model is under-designed.
- Conversation logic and business logic get mixed together
- Tools are callable without a hard policy checkpoint
- Observability is too shallow to debug failures quickly
- Evaluation happens ad hoc, not as a release discipline
- Human approval is bolted on too late
So the core design question changes from Which model should we choose? to What control architecture keeps this reliable, auditable, and safe?
A layered architecture that actually holds up
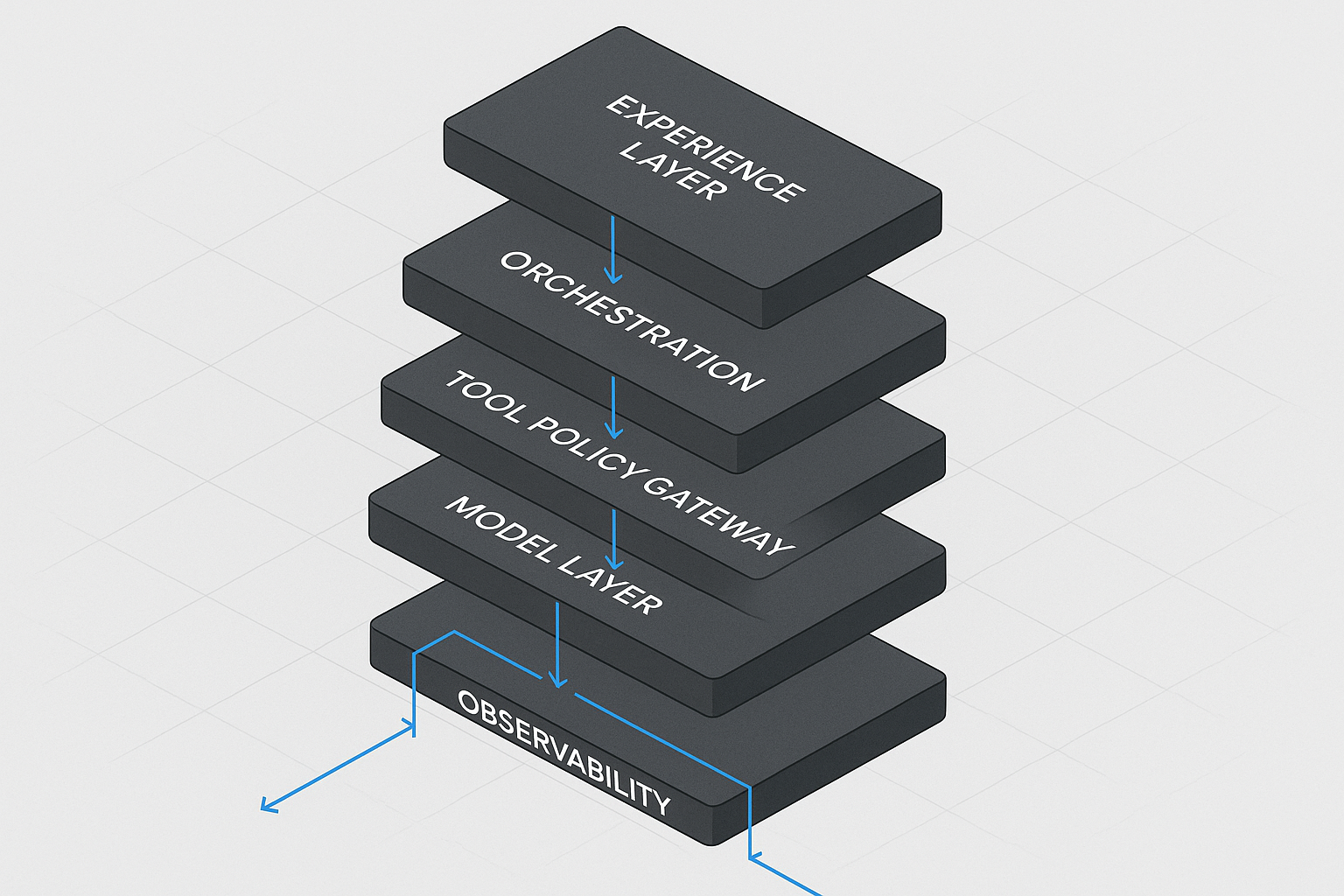
In practice, when you separate responsibilities cleanly, agent systems become governable. Here’s the stack I recommend.
1) Experience Layer (where users interact)
Teams, portal UI, service desk frontends, internal apps.
- Identity-aware session entry
- Intent + context capture
- Clear response rendering with provenance
- Human escalation controls
Keep it thin. This is interaction orchestration, not business execution.
2) Orchestration Layer (decision flow runtime)
This layer decides what happens next, and why.
- Goal decomposition and routing
- State transitions and handoffs
- Retries/timeouts/circuit breakers
- Fallback paths when confidence drops
My strong recommendation for v1: avoid full autonomy (especially in regulated or high-impact workflows). Constrained workflows with explicit transitions are less glamorous—and much more survivable.
3) Tool Gateway (non-negotiable policy choke point)
Every tool call should pass through one governed gateway.
- Tool registry and allow-listing
- Input/output schema enforcement
- RBAC/ABAC + data classification policy checks
- Rate limiting and idempotency support
- Immutable audit records per action
If agents can call core systems directly, you don’t have an agent platform—you have unmanaged blast radius.
4) Knowledge & Retrieval Layer (RAG as infrastructure)
RAG should be an operational service, not a one-off helper inside each app.
- Shared indexing pipelines (docs, tickets, structured data)
- Hybrid retrieval and reranking
- Access-trimmed context injection
- Freshness and provenance metadata
In many enterprise rollouts, retrieval failures are often systems failures (index quality, access trimming, ranking choices) more than pure prompting mistakes.
5) Model Layer (replaceable components, stable contracts)
- Task-based model routing (speed vs depth)
- Structured outputs with schema contracts
- Prompt/version control and safe rollout
- Tool-use permissions tied to policy state
Don’t hardwire your architecture to one model behavior. Keep the contract stable and components swappable.
6) Safety, Evals, and Observability Layer (where trust is earned)
- Pre/post policy and safety checks
- End-to-end trace capture
- Offline eval suites for regressions
- Online SLOs: latency, quality, escalation, cost
- Kill switch and rollback paths
If you can’t replay and explain decisions, you’re still in prototype mode, no matter how nice the UI is.
A practical stack split: Azure + OpenAI + Python + .NET
For mixed enterprise teams, this split works well:
- Python: rapid agent iteration, eval harnesses, data-heavy adapters
- .NET: enterprise APIs, typed contracts, transaction-heavy integration services
- Azure: identity, policy, networking, and operations backbone
- OpenAI/Azure OpenAI: reasoning + tool-capable model execution
Polyglot is fine. Inconsistent standards are not. Shared schemas, shared traces, and shared release gates are what keep the system coherent.
Implementation phases
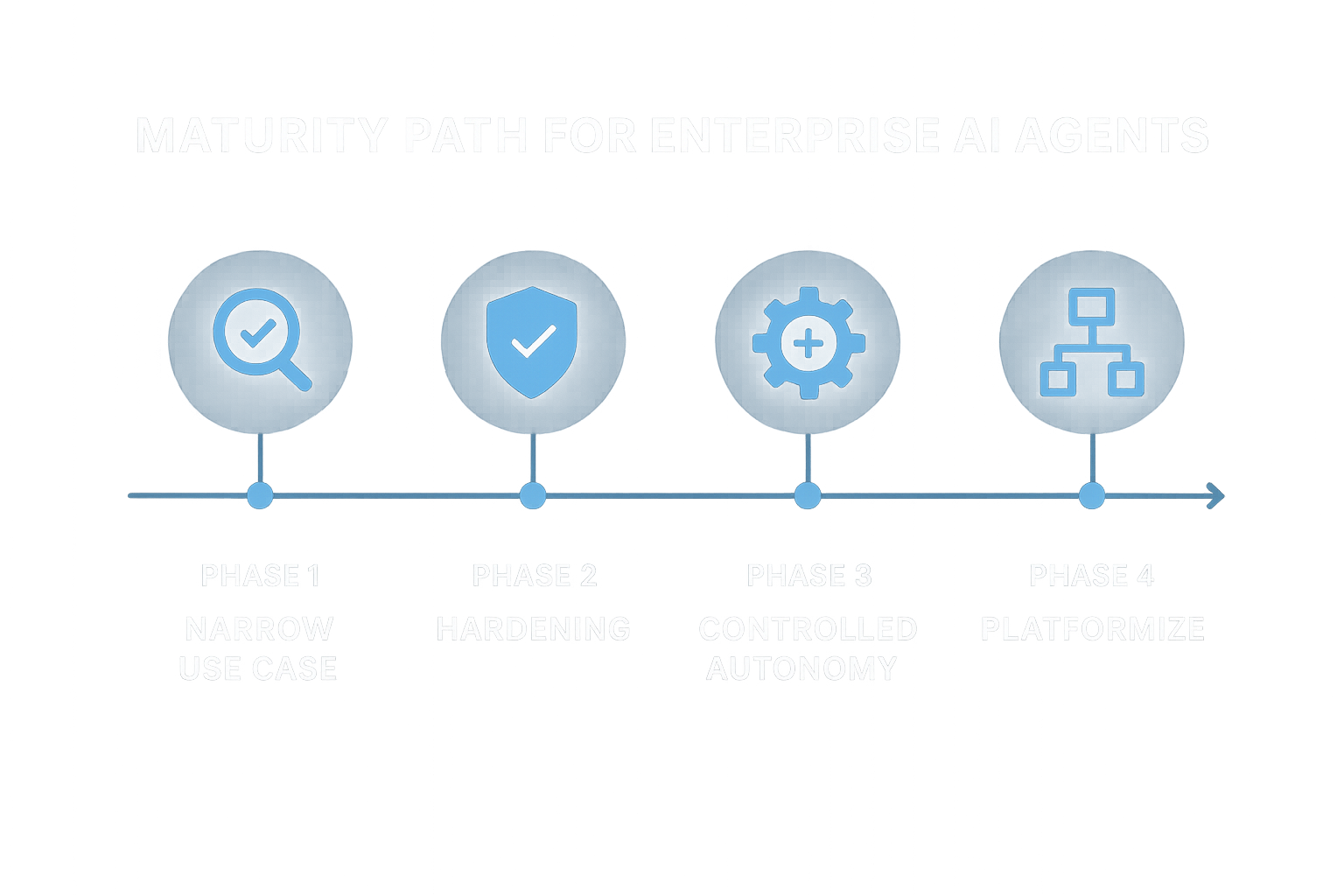
Phase 1: Pick one narrow, high-value workflow
Examples: support triage, contract summarization with approval, internal knowledge assistant with citations.
Phase 2: Harden before expansion
- Enforce gateway policies
- Instrument full traces
- Create baseline eval datasets
- Define forbidden autonomous actions
Phase 3: Add controlled autonomy
Automate low-risk tasks; route medium/high-risk actions through human checkpoints with clear rationale attached.
Phase 4: Platform-ize
Turn successful patterns into reusable components, add onboarding playbooks, and set architecture review gates for new agent use cases.
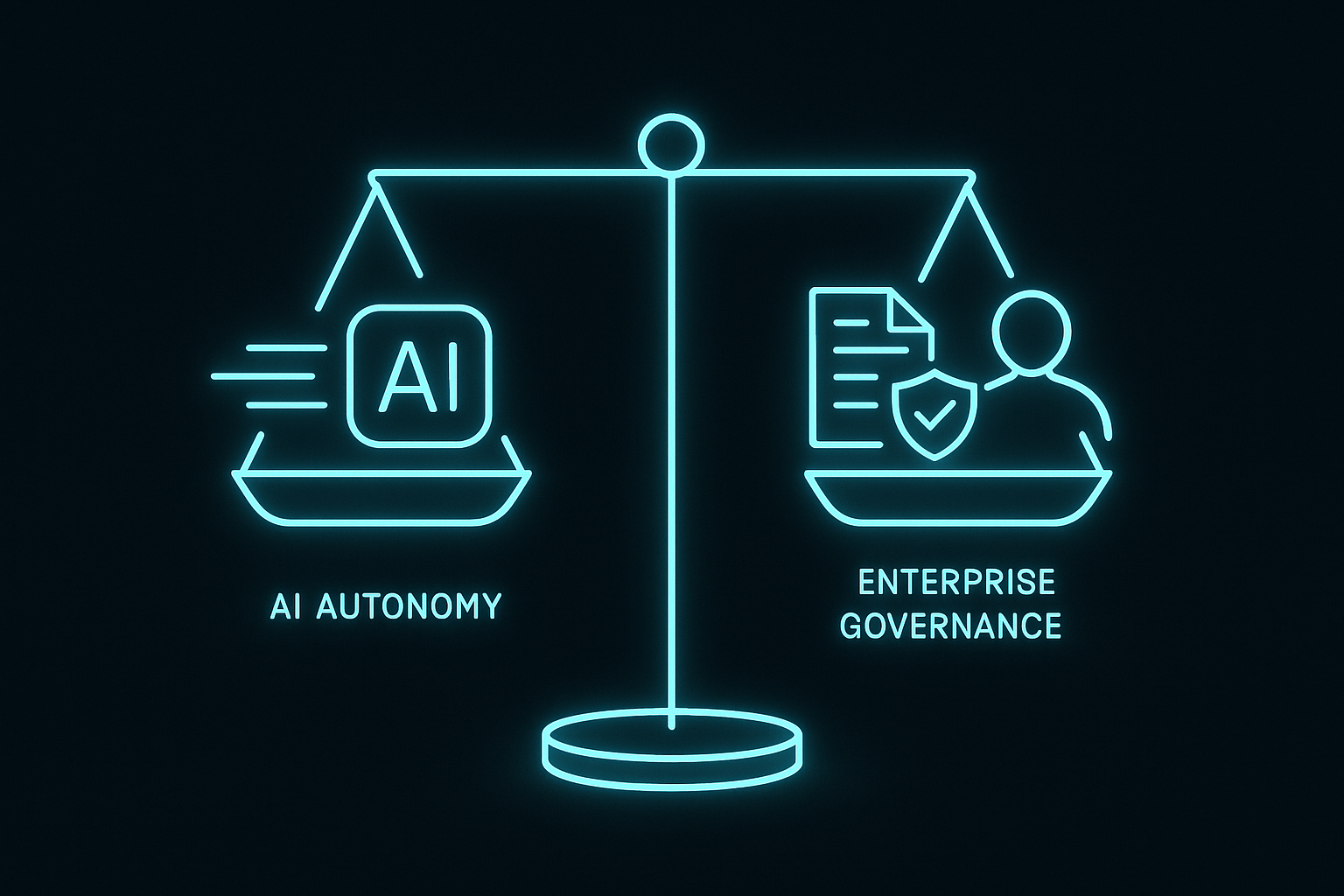
The trade-offs you should acknowledge early
- Control vs speed: guardrails slow some flows, but prevent expensive incidents
- Generality vs reliability: domain-specific agents win in production
- Latency vs depth: better reasoning often costs more time and budget
- Autonomy vs accountability: each autonomous action needs ownership
- Central standards vs team freedom: federation works only with strong contracts
A quick maturity check for 2026
Your architecture is maturing if your team can quickly answer:
- Which policy authorized this tool call?
- Which sources shaped this output?
- Which model/prompt version executed this step?
- What changed in quality after the last release?
- Can we replay this decision path end-to-end?
- Can we disable this workflow safely within minutes?
Final thought
Enterprise agents are not an experiment you “ship and hope.” They’re a systems program. In practice, the teams that succeed long-term prioritize operational reliability first, then scale autonomy with measured evidence.
Start narrow. Instrument deeply. Expand deliberately.