How to Build Production Agents with OpenAI Responses API + Azure Foundry Agent Service

Most teams proved they can build an agent in a week. Far fewer proved they can run one safely in production for six months.
That is the shift we are now living through in 2026: from demo intelligence to operational intelligence. The bottleneck is no longer “can the model answer?” It is “can the system be governed, observed, and recovered at 2:00 AM?”
Two platform moves made this transition practical:
- OpenAI’s Responses API becoming the default primitive for agentic workflows (instead of stitching chat + tools + state manually)
- Azure Foundry Agent Service giving enterprises a managed runtime with policy, identity, network controls, and observability
If your current stack is a mix of Semantic Kernel planners, AutoGen group chats, and custom glue code, this post gives you a concrete path forward—without locking you into one framework mindset.
1) The 2026 shift: from “works” to “operates”
Production agent systems are now judged by five things:
- Bounded behavior (tool loops, retries, and spend ceilings)
- Traceability (what happened, why, and with which inputs)
- Policy enforcement (data boundaries, identity, and approvals)
- Rollback safety (prompts/tool schema changes are release-managed)
- Unit economics (predictable p95 latency and cost per successful task)
The biggest anti-pattern I still see: teams optimize for agent cleverness before they optimize for operating model. In production, boring architecture wins.
2) What changed: Responses API + Foundry Agent Service
OpenAI Responses API changes
- Single API primitive for generation + tool usage
- Native tool orchestration model (built-in tools + custom functions)
- Cleaner evolution path for reasoning-centric models
- State chaining via response IDs/conversation primitives instead of rebuilding context manually each turn
Practically, this removes a lot of brittle orchestration code from application layers.
Azure Foundry Agent Service changes
- Managed runtime abstraction for enterprise agents
- Integrated security/compliance posture with Azure controls
- Centralized observability and policy hooks
- Composable model/tool/orchestration options under one service umbrella
Practically, this reduces platform-engineering drag for regulated or multi-team environments.
Note: Microsoft documentation and portal labels may alternate between “Azure AI Foundry” and “Microsoft Foundry”; the Agent Service capabilities discussed here refer to that same managed agent runtime direction.
3) Reference architecture you can actually run
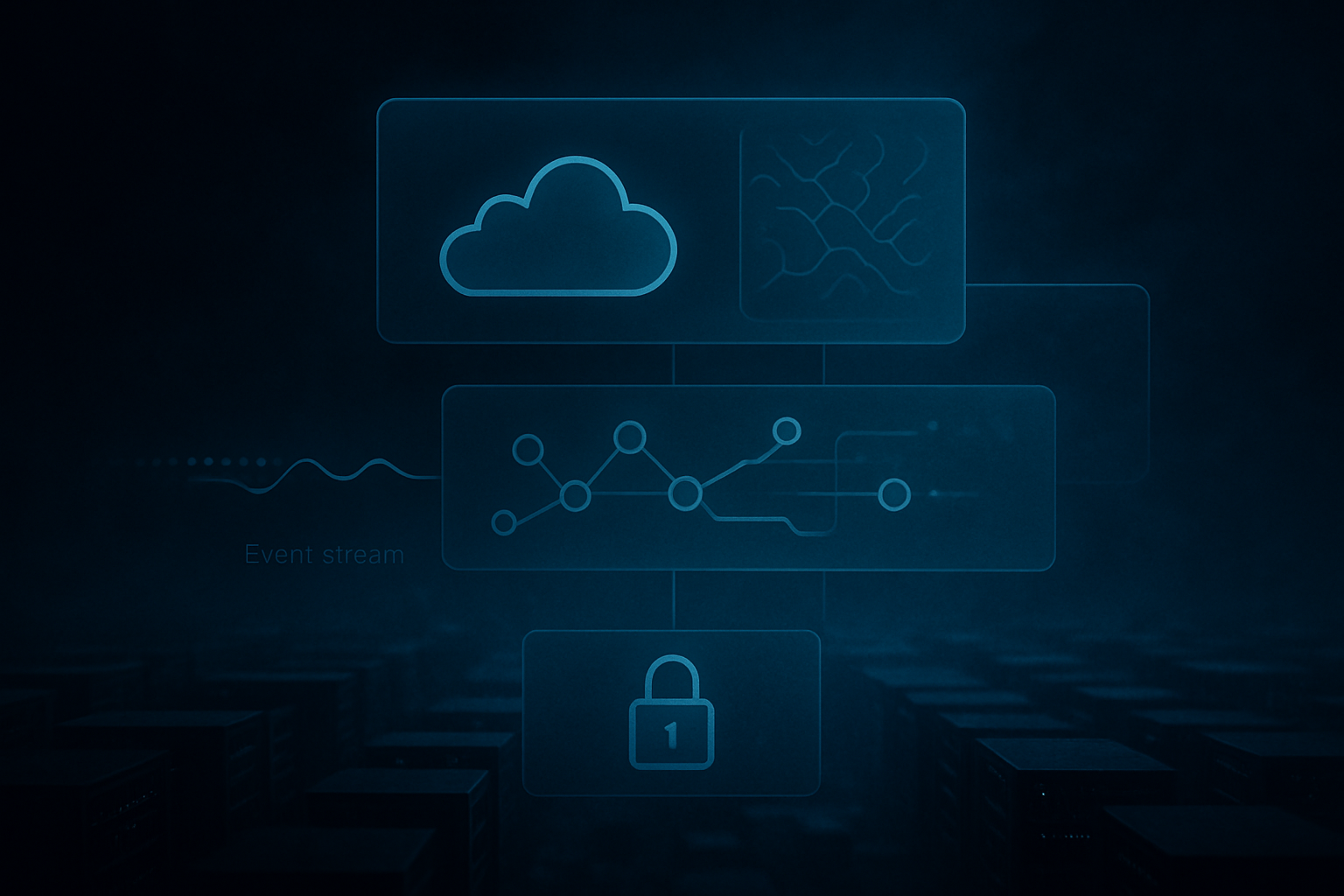
Keep the architecture split into three planes:
- Control plane: prompts, tool contracts, policy config, release versions
- Runtime plane: API ingress, agent executor, tool adapters, queue/workers
- Observability plane: traces, cost metrics, outcome metrics, policy events
The trick is enforcing versioned contracts between these planes. Agent failures are often integration failures disguised as model failures.
4) Path A: OpenAI-native implementation
Use this path when you want maximum product velocity and you own your own runtime controls.
Minimal Python baseline
from openai import OpenAI
client = OpenAI()
def get_ticket_status(ticket_id: str) -> dict:
# your system call here
return {"ticket_id": ticket_id, "status": "in_progress"}
resp = client.responses.create(
model="gpt-5",
input="Check ticket INC-24531 and summarize next action.",
tools=[{
"type": "function",
"name": "get_ticket_status",
"description": "Returns incident status",
"parameters": {
"type": "object",
"properties": {"ticket_id": {"type": "string"}},
"required": ["ticket_id"]
}
}],
tool_choice="auto"
)
print(resp.output_text)
Minimal .NET baseline
using OpenAI.Responses;
var client = new OpenAIResponseClient(apiKey);
var request = new ResponseCreationOptions
{
Model = "gpt-5",
Input = "Summarize customer sentiment from case batch 417.",
Tools =
{
// Register function tools with strict schema
}
};
Response response = await client.CreateResponseAsync(request);
Console.WriteLine(response.OutputText);
Operational guidance for Path A:
- Put tool calls behind a gateway with timeout budget + idempotency key
- Store request/response metadata for replay (not raw secrets)
- Cap steps and retries to prevent runaway loops
- Treat prompts and tool schemas as versioned deploy artifacts
5) Path B: Azure Foundry Agent Service implementation
Use this path when enterprise controls matter more than raw iteration speed.
Typical shape:
- Define agent instructions and tool set in Foundry project
- Attach enterprise connectors/data sources with explicit RBAC scope
- Run through managed orchestration runtime
- Emit telemetry to Azure Monitor / App Insights
- Apply network and identity boundaries (private endpoints, managed identity, key vault references)
Operational guidance for Path B:
- Use environment promotion (dev → staging → prod) with policy checks at each stage
- Keep slot-specific or environment-specific settings explicitly separated
- Treat content filters and safety policies as first-class release configuration
- Design fallback behavior when downstream tools or connectors throttle
6) Python and .NET implementation notes that save pain
- Schema-first tools: define JSON schema once, generate language bindings for Python + .NET to avoid drift
- Shared contract tests: same fixtures run against both service implementations
- Correlation IDs everywhere: API ingress → agent turn → each tool call
- Deterministic retries: idempotent tool endpoints + retry budget + jitter
- State boundaries: store business state in your DB, not only in conversational context
Python-specific notes: keep async tool clients isolated behind adapters so you can swap providers without changing prompt/instruction layers. Use Pydantic (or equivalent) for strict inbound/outbound validation and fail fast when tool responses are malformed.
.NET-specific notes: model tool contracts as strongly typed DTOs and centralize serialization settings (case, null handling, enum behavior). Most cross-language bugs in mixed stacks are boring serialization mismatches, not model quality issues.
Cross-stack release pattern: version agent instructions, tool schemas, and policy files independently from application binaries. In practice, this means your rollback can revert prompt/tool behavior without forcing a full application redeploy, which shortens incident recovery significantly.
One practical pattern is to keep a thin “agent coordinator” service language-agnostic, then implement high-performance tools in the language best suited to each subsystem.
Another pattern that scales well is a “golden transcript” suite: 20–50 representative user journeys replayed on every release. Score each run for correctness, policy compliance, latency, and token cost. This gives you a regression harness that both engineers and product owners can understand.
7) Cost / latency / reliability scorecard

| Dimension | OpenAI-native Path A | Foundry-managed Path B |
|---|---|---|
| Time-to-first-agent | Fastest | Moderate |
| Platform control | You build/own more | Managed controls included |
| Latency tuning | High flexibility | Good, but platform-mediated |
| Enterprise governance | Custom implementation | Stronger out of the box |
| Ops burden | Higher | Lower to moderate |
| Best fit | Product teams optimizing speed | Enterprise teams optimizing trust |
There is no universal winner. Pick based on your bottleneck, not on hype.
8) Migration checklist from Semantic Kernel / AutoGen stacks

- Inventory current flows: identify planners, tool routers, memory stores, human-in-loop checkpoints
- Map orchestration primitives: old planner loops → Responses/Foundry orchestration model
- Normalize tool schemas: remove framework-specific wrappers where possible
- Introduce contract tests first: migrate tooling only after baseline parity is proven
- Migrate one workflow at a time: start with highest-value, lowest-regulation process
- Run dual execution period: compare output quality, latency, and failure rates before cutover
- Cut over with rollback: release as configuration switch, not as hard replacement
9) Common failure modes (and real mitigations)
- Failure: tool-call storms.
Mitigation: max-step caps, per-tool budgets, global circuit breaker. - Failure: prompt drift across environments.
Mitigation: version prompts in source control and promote via release pipeline. - Failure: hidden schema mismatches.
Mitigation: schema contract CI + backward compatibility checks. - Failure: “green health checks” but broken outcomes.
Mitigation: include business-path synthetic tests, not only /health endpoints. - Failure: impossible post-incident analysis.
Mitigation: structured event logs per agent step with correlation and cost metadata.
10) Final recommendation
If you are a product team shipping net-new capability and can own runtime engineering, start with OpenAI Responses API and design strict operational guardrails from day one.
If you are an enterprise team with compliance, IAM, and network constraints as top priorities, move toward Azure Foundry Agent Service and let the platform absorb more of the control plane burden.
Either way, the winning strategy in 2026 is the same: keep your agent architecture framework-agnostic, contract-driven, and observable. Demos impress. Operations compound.
If you’re planning migration this quarter, start with one workflow, instrument it deeply, and force yourself to publish a weekly reliability scorecard. That single habit will surface more truth than ten architecture meetings.